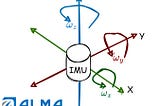
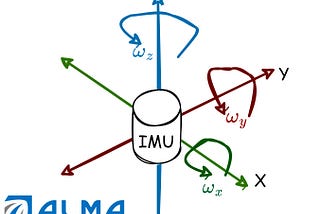
PinnedDr Barak OrinTowards Data ScienceWhat is IMU?IMU (Inertial Measurement Unit) is one of the common sensor to provide motion data in a time-series format. In this post we review it.Jul 31, 20211Jul 31, 20211
PinnedDr Barak OrinTowards Data ScienceValue-based Methods in Deep Reinforcement LearningDeep Reinforcement learning is one of the rising-up fields in the last years. A good approach to start with is the value-based method…Jan 30, 2021Jan 30, 2021
PinnedDr Barak OrinTowards AIExploring The Last Trends of Random ForestThe random forest model is considered one of the promising ML ensemble models. Recently it becomes highly popular. In this post, we review…Dec 11, 2020Dec 11, 2020
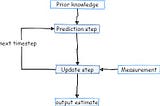
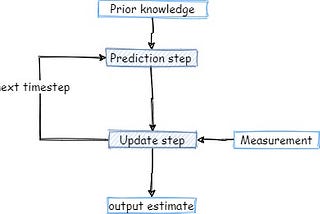
PinnedDr Barak OrinTowards Data ScienceKalman filter Celebrates 60 years — An Intro.The Kalman filter is one of the most influential ideas used in Engineering, Economics, and Computer Science for real-time applications.Dec 5, 20202Dec 5, 20202
PinnedDr Barak OrinTowards Data ScienceDeep Learning in Geomtry: Arclentgh LearningA fundamental problem in geometry was solved using a Deep Neural Network (DNN). We learned a geometric property from examples. As the…Nov 7, 2020Nov 7, 2020
Dr Barak OrinTowards AISmall Language Models (SLMs) in Enterprise: A Focused Approach to AIOne size does not fit all. Large language models (LLMs) like GPT-4 have certainly grabbed headlines with their broad knowledge and…Apr 101Apr 101
Dr Barak OrinDataDrivenInvestorArtificial Intelligence: A Historical Journey Introduction (AI/ML/DL)Exploring the Evolution of Artificial Intelligence: Milestones, Breakthroughs, and Future ProspectsMar 221Mar 221
Dr Barak OrinMetaOr Artificial IntelligenceAI for Cybersecurity| Voice SynthesisIn this post, we introduce AI-based voice synthesis technologies and their increasing influence on cybersecurity practices.Jan 17Jan 17
Dr Barak OrinMetaOr Artificial IntelligencePeDistNet: AI-based Indoor Navigation for PedestriansRevolutionizing Distance Estimation for Pedestrian using Smartphone: A Deep Dive into Advanced LSTM and Convolutional Model Architecture…Dec 14, 2023Dec 14, 2023